KANO模型
1. 概述
我们在做项目做产品的过程中,经常会接到来自PM/领导/业务方等等的各种需求。有时候哪怕一个小功能、小页面都会争得不可开交。这个时候怎么办呢?到底应该听谁的呢?哪个需求优先级高?哪种呈现方法是更靠谱的呢?
今天我们就来聊聊一个非常实用的需求分级方法——KANO模型。这是一个典型的定性分析模型,一般不直接用来测量用户的满意度,常用于识别用户对新功能的接受度。
在KANO模型中,根据不同类型的需求与用户满意度之间的关系,可将影响用户满意度的因素分为五类:基本型需求、期望型需求、兴奋型需求、无差异需求、反向型需求。
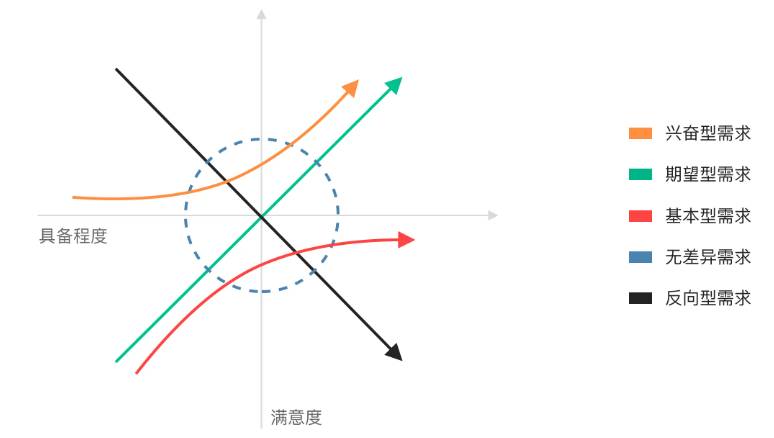
- 必备型需求(必须有):即常说的痛点。对于用户而言,这些需求是必须满足的,理所当然的。当不提供此需求,用户满意度会大幅降低。这类是核心需求,也是产品必做功能。
- 期望型需求(应该有):当提供此需求,用户满意度会提升;当不提供此需求,用户满意度会降低。通常作为竞品之间比较的重点。
- 兴奋型需求(可以有):惊喜型产品功能,超出用户预期,往往能带来较高的忠诚度。不提供也不会降低用户满意度。
- 无差异需求(可以没有):用户不在意的需求,对用户体验毫无影响。尽量规避做此类型功能。
- 反向型需求(避免有):用户根本都没有此需求,提供后用户满意度反而下降。
2. 案例演示
实现思路:通过创建一份调研问卷,收集用户反馈;然后引用这份问卷的数据源创建分析报告,构建图表。
2.1 设计、发放调研问卷
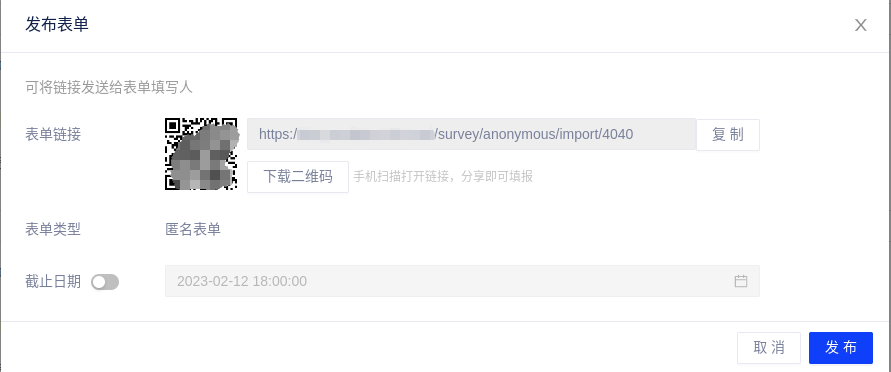
(1)打开本产品的数据填报模块,创建一个在线问卷,详情可参考流式表单;
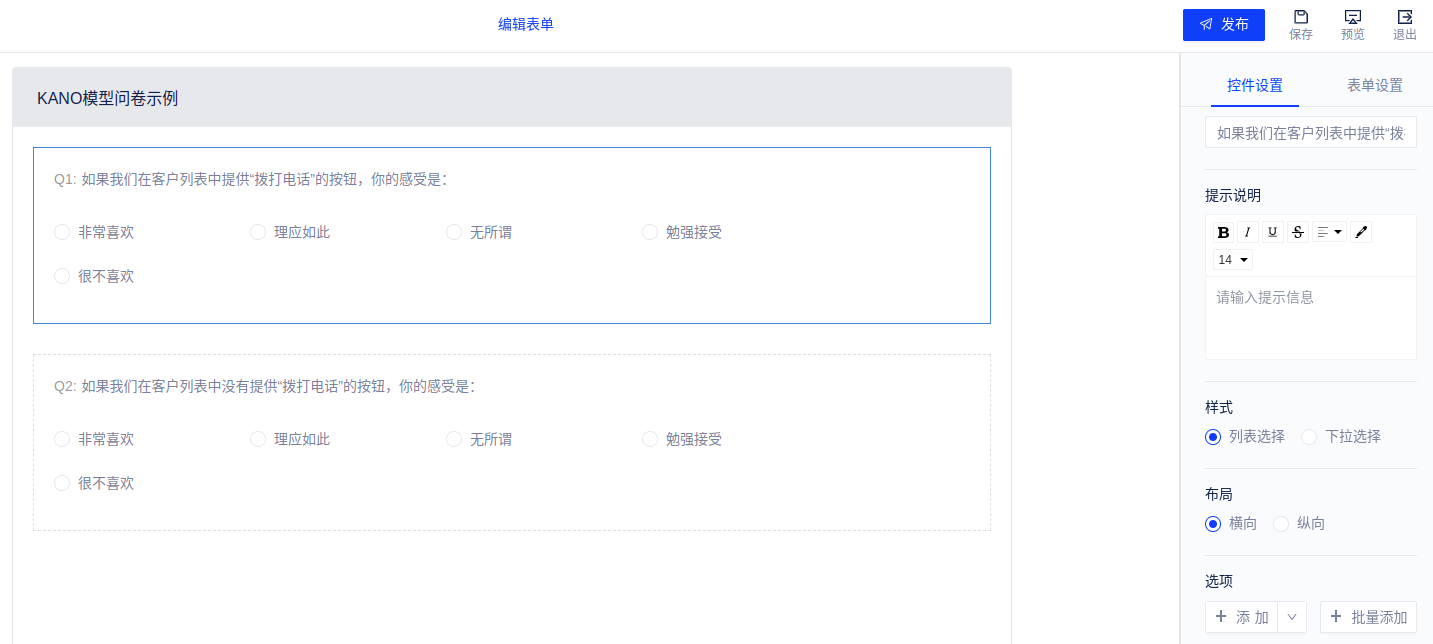
(2)KANO 问卷中每个功能都要有正向和反向两个问题,如下图所示:
(3)将设计好的问卷发布,发放给目标用户并邀请填写;
2.2 清洗案例数据
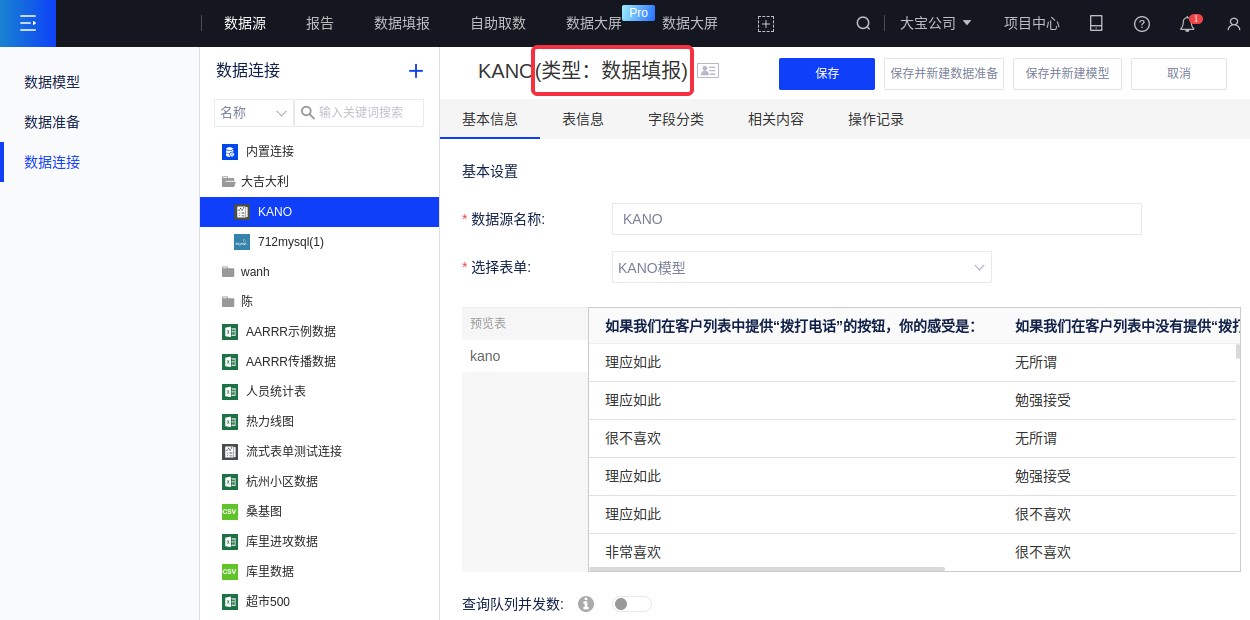
(1)打开本产品的数据源模块,创建一个类型为数据填报的数据连接,然后选择上文创建的表单;
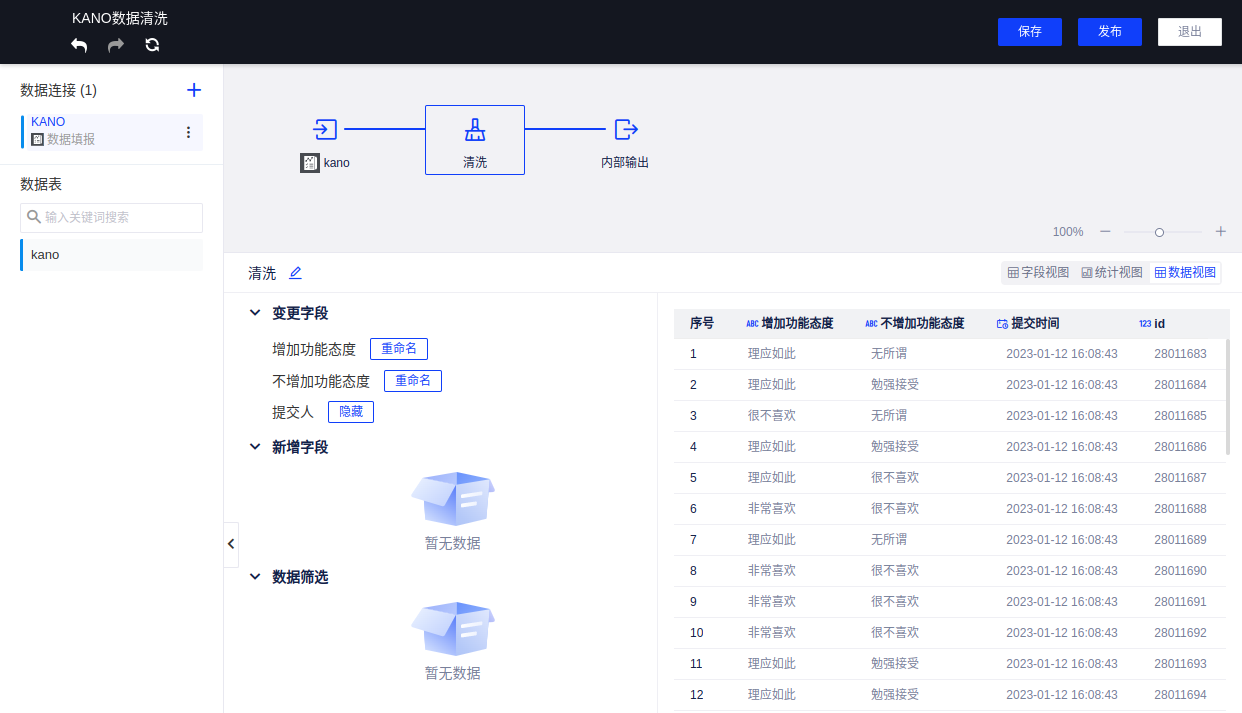
(2)在数据准备中,对该数据连接做下简单的数据清洗,便于后面的报告制作,详情可参考数据处理;
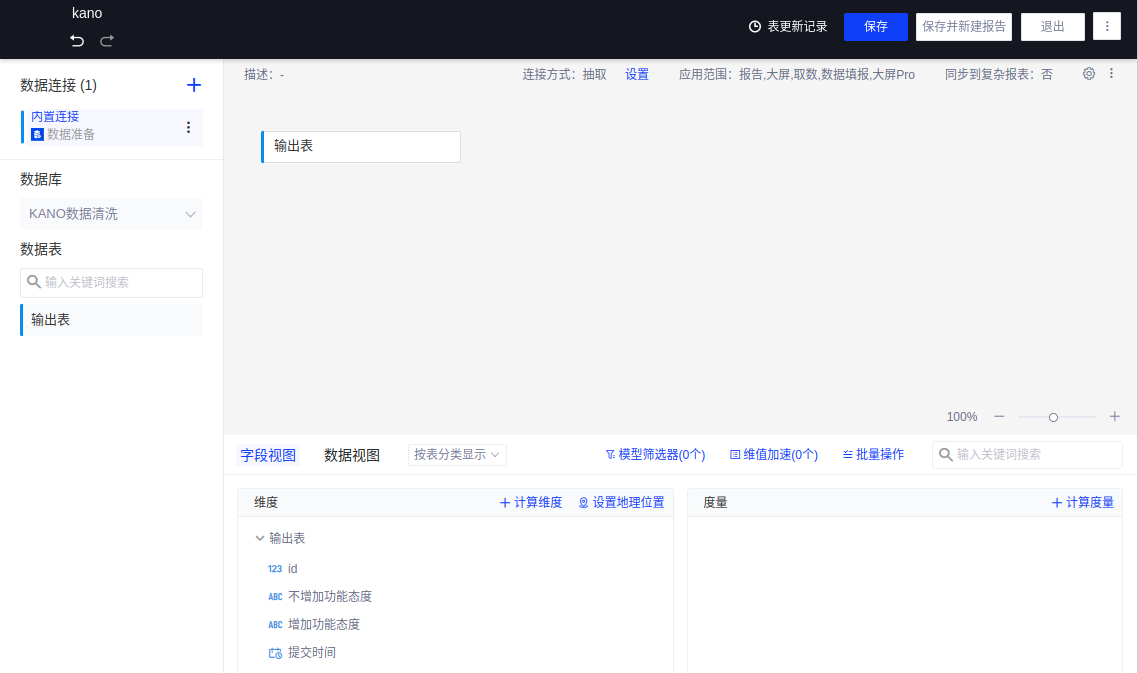
(3)引用上一步发布的数据准备,创建一个名为“kano”的数据模型,清洗、建模工作结束。
2.3 构建计算字段
进入报告编辑页面,开始创建需要的计算字段。
(1)创建一个名为“合并态度”的计算字段,合并态度 = [增加功能态度]+[不增加功能态度];
按照用户对「增加功能态度」与「不增加功能态度」,我们可以通过下表定位某功能对于用户来说是什么需求。
M:基本(必备)型需求;O:期望(意愿)型需求;A:兴奋(魅力)型需求;I:无差异型需求;R:反向(逆向)型需求;Q:可疑结果
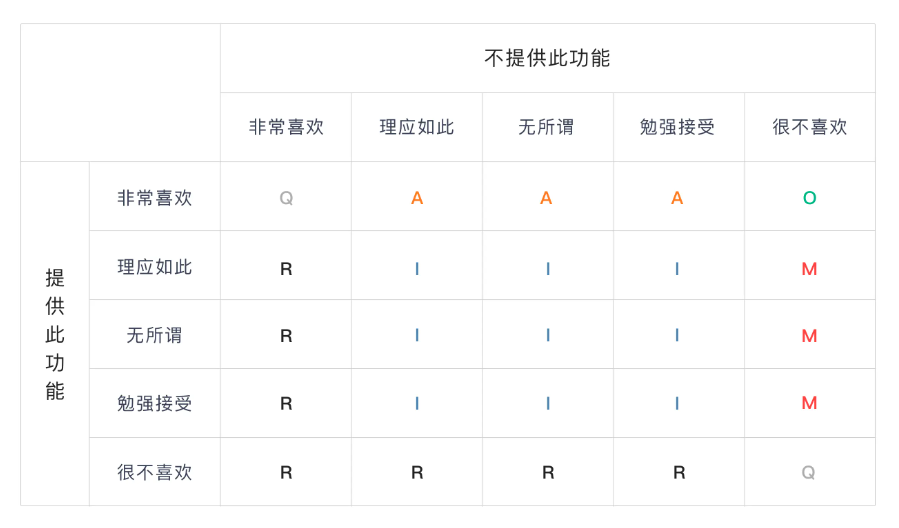
(2)上一步已经知道如何定位需求类型,接下来要做的就是在分析表中定位判断,使用“CASE条件函数”创建“类型”字段,如下图所示:
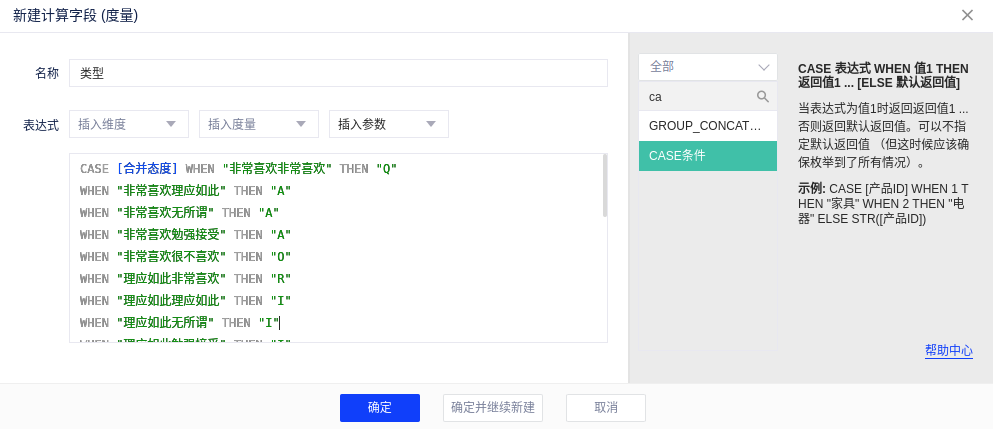
类型 = CASE [合并态度] WHEN “非常喜欢非常喜欢” THEN “Q” WHEN “非常喜欢理应如此” THEN “A” WHEN “非常喜欢无所谓” THEN “A” WHEN “非常喜欢勉强接受” THEN “A” WHEN “非常喜欢很不喜欢” THEN “O” WHEN “理应如此非常喜欢” THEN “R” WHEN “理应如此理应如此” THEN “I” WHEN “理应如此无所谓” THEN “I” WHEN “理应如此勉强接受” THEN “I” WHEN “理应如此很不喜欢” THEN “M” WHEN “无所谓非常喜欢” THEN “R” WHEN “无所谓理应如此” THEN “I” WHEN “无所谓无所谓” THEN “I” WHEN “无所谓勉强接受” THEN “I” WHEN “无所谓很不喜欢” THEN “M” WHEN “勉强接受非常喜欢” THEN “R” WHEN “勉强接受理应如此” THEN “I” WHEN “勉强接受无所谓” THEN “I” WHEN “勉强接受勉强接受” THEN “I” WHEN “勉强接受很不喜欢” THEN “M” WHEN “很不喜欢非常喜欢” THEN “R” WHEN “很不喜欢理应如此” THEN “R” WHEN “很不喜欢无所谓” THEN “R” WHEN “很不喜欢勉强接受” THEN “R” WHEN “很不喜欢很不喜欢” THEN “Q”
2.4 制作图表
(1)选择“图表”控件,在画布上画出“图表”;
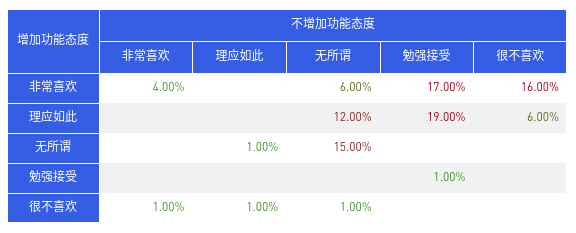
(2)将字段“增加功能态度”、“不增加功能态度”和“类型”分别拖入yx轴和标签,并设置[快速表计算-总额百分比]得到下表;

(3)对样式稍作调整,完成图表制作。
3. 结论分析
从上表中不难看出,该项功能在6个维度上均有得分,将相同维度的比例相加后,可得到6个属性维度的占比总和。总和最大的一个属性维度,便是该功能的属性归属。
3.1 KANO属性
| I:无差异型 | A:兴奋型 | O:期望型 | M:必备型 | R:反向型 | Q:可疑结果 |
|---|---|---|---|---|---|
| 48% | 23% | 16% | 6% | 3% | 4% |
可看出该项功能属于无差异型需求。即说明有没有这个功能,用户都不怎么在意。
如果您只判断这一个需求,那么进行到这一步就可以到此为止了。如果涉及到多个需求的排序分级,你还需进行计算 better-worse系数。
3.2 Better-worse系数
表示某功能可以增加满意或者消除不喜欢的影响程度。
Better,可以解读为增加后的满意系数。Better的数值通常为正,代表如果产品提供某种功能或服务,用户满意度会提升。正值越大/越接近1,则表示用户满意度提升的效果会越强,满意度上升的越快。
better =(A占比+O占比)/(A占比+O占比+M占比+I占比)`
Worse,可以叫做消除后的不满意系数。Worse的数值通常为负,代表产品如果不提供某种功能或服务,用户的满意度会降低。其负值越大/越接近-1,则表示对用户不满意度的影响最大,满意度降低的影响效果越强,下降的越快。
worse = -1*(O占比+M占比)/(A占比+O占比+M占比+I占比)
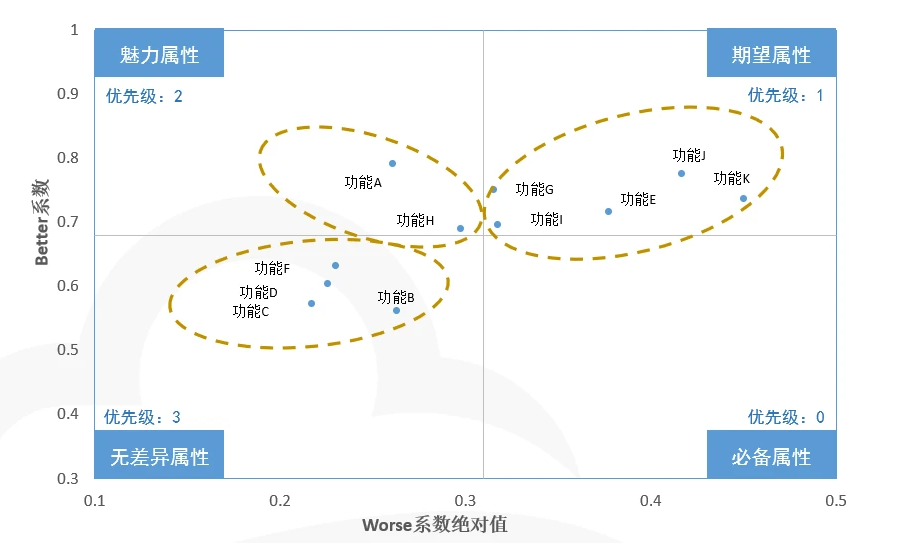
例如:某产品希望优化10项功能,但是不知道哪些是用户需要的。通过KANO调研分析,可以分别算出10项功能的better-worse系数。根据better-worse系数值,将散点图划分为四个象限以确立需求优先级。如下图所示: